Why I'm Building Beep
At Chatarmin, I do a lot of infrastructure work.
Most of our services run on Hetzner and VPS-based infrastructure instead of the typical managed cloud platforms people reach for by default. The reason is simple: it is cheaper, easier to reason about in many cases, and gives us more control over how our systems actually run.
But that tradeoff comes with a cost.
When you move away from platforms like Railway, Render, Fly, Vercel, or the larger cloud providers, you also move away from a lot of the guardrails those platforms give you by default.
Deployments become your problem. Observability becomes your problem. Server health becomes your problem. Access control becomes your problem. Scaling becomes your problem. Incidents become your problem.
A server spikes at 2am? You better hope someone is awake.
A background worker starts eating memory? You need enough visibility to notice before customers do.
A service needs to scale beyond one machine? You now have to think about provisioning, routing, service discovery, load balancing, health checks, deployments, logs, secrets, and rollback behavior.
This is the real tradeoff of running on VPS infrastructure.
You save money, but you inherit responsibility.
That responsibility is not always bad. In fact, I think a lot of teams should understand more about the systems they run. Infrastructure should not be complete magic. The problem is that most teams do not want to build an internal platform before they can ship their actual product.
There is a gap between “use an expensive managed platform for everything” and “manually operate a collection of servers with scripts, dashboards, and prayers.”
Beep exists because of that gap.
The middle ground
I do not think every company needs Kubernetes.
I also do not think serious companies should rely on infrastructure setups that only work because one engineer remembers how everything is wired together.
There should be a better middle ground.
A platform where teams can deploy to VPS infrastructure, keep the cost benefits, and still get the operational guardrails they need to run real products.
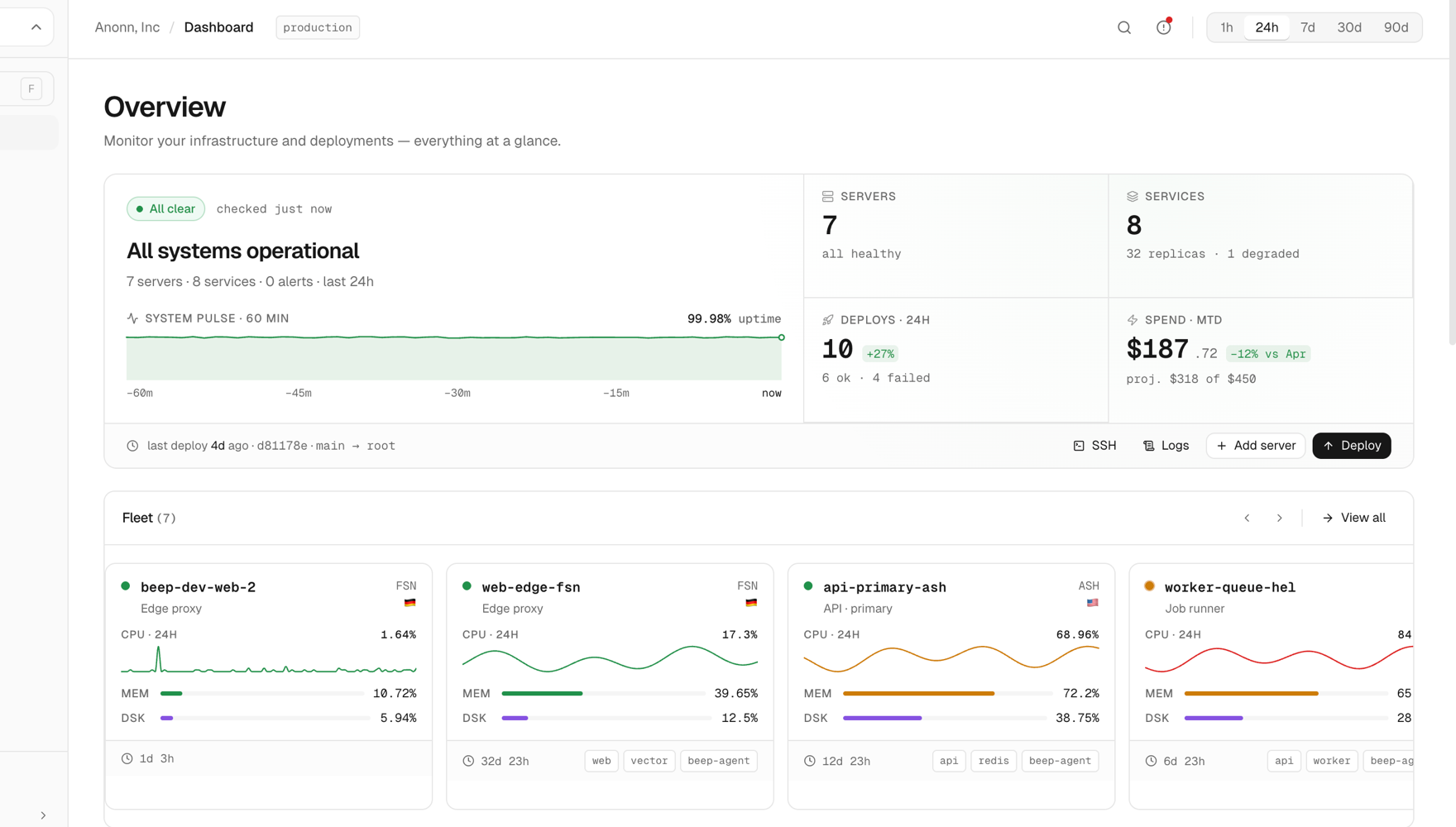
That means things like:
- simple deployments
- service health checks
- logs and metrics
- server monitoring
- autoscaling
- custom domains
- environment variables and secrets
- access control
- rollback support
- background workers
- databases
- cron jobs
- alerts before things become incidents
- visibility into what is running and where
The goal is not to hide infrastructure completely.
The goal is to make it manageable.
The cost problem
Cloud platforms are useful because they remove a lot of operational work. That is the point.
You push code, get a URL, add environment variables, maybe connect a database, and the platform handles the rest.
That experience is powerful. It lets small teams ship quickly without thinking about servers, networking, process management, TLS certificates, deployments, logs, and all the small details that make production software annoying.
But convenience compounds into cost.
At small scale, the cost can feel acceptable. As the system grows, as more services get added, as more workers run, as more preview environments get created, as more databases and background jobs appear, the bill can start to feel disconnected from the actual infrastructure being used.
This is one reason VPS infrastructure remains attractive.
A well-sized Hetzner server can run a lot of software for a fraction of what many managed platforms would charge. For teams that know what they are doing, the economics can be very hard to ignore.
The problem is that cheap infrastructure should not mean fragile infrastructure.
That is the part I keep thinking about.
How do you keep the cost and control of VPS infrastructure, while getting more of the safety, visibility, and workflow of a modern cloud platform?
That is the shape of Beep.
Why not just use Coolify?
Coolify is cool.
For hobby projects, internal tools, side projects, and early deployments, it solves a real problem. It gives people a way to self-host applications without starting from zero.
But I do not think tools like that are enough for companies running serious revenue through their systems.
Once a product is doing millions in revenue, the expectations change.
You need stronger access control. You need better reliability guarantees. You need autoscaling. You need auditability. You need better operational visibility. You need safer deployments. You need guardrails around who can do what. You need the system to support a team, not just one technical person.
At that point, “it deploys my app” is not enough.
You need to operate the app.
You need to understand what is happening when something goes wrong. You need alerts before customers are affected. You need to know who changed what. You need rollback behavior. You need visibility into server pressure. You need to see whether queues are falling behind. You need to know whether a deployment failed because of the build, the runtime, the network, the database, or a bad environment variable.
That is where many self-hosted deployment tools start to feel incomplete.
They help you deploy.
They do not fully help you operate.
Beep is not just about pushing code to a server. It is about giving small teams the missing operational layer around VPS infrastructure.
Preview environments should include the whole system
Another problem I keep thinking about is preview environments.
For a lot of frontend teams, preview environments already feel normal. You open a pull request, Vercel gives you a preview URL, and someone can review the change before it goes live.
That is useful, but it only solves part of the problem.
Most real products are not just frontend applications. They have backends, databases, queues, workers, cron jobs, webhooks, caches, environment variables, third-party integrations, and data flows that need to work together.
A frontend preview is not enough when the change being reviewed affects the backend, the database, the checkout flow, a background job, an API contract, or a customer data pipeline.
What I want is a full-stack preview environment.
Open a pull request and get a temporary environment with the frontend, backend, database, workers, and required services running together. Not just a screenshot of the UI. Not just a static frontend preview. A real environment where the team can test the actual system before merging.
This matters even more now that AI agents are becoming part of engineering workflows.
If an engineer or an AI agent makes a change, the review process should not rely only on reading code and hoping the system still works. The change should be deployed somewhere safe. The reviewer should be able to click through it, test the API, inspect logs, see migrations, check background jobs, and understand what changed in a real running environment.
But this should not cost a fortune.
Spinning up a full copy of production for every pull request can become expensive very quickly if it is built on traditional cloud assumptions. That is part of what makes VPS-based infrastructure interesting. If managed properly, it should be possible to create useful temporary environments without paying enterprise-level prices for every preview.
The hard part is orchestration.
You need to know what services belong together. You need isolated environments. You need temporary databases. You need safe secrets handling. You need predictable cleanup. You need routing. You need logs. You need access control. You need limits so one preview environment does not waste resources forever.
That is the kind of problem Beep should solve.
Not just deployment.
A better workflow for building, reviewing, testing, and operating full-stack products.
The problem I keep seeing
Small teams usually get forced into one of two bad choices.
The first choice is to use a managed platform that is easy at the beginning but can become expensive or limiting as the product grows.
The second choice is to run their own servers and slowly rebuild the parts of a platform they lost: deploy scripts, monitoring, alerts, dashboards, access control, scaling logic, backups, secrets, logs, and incident processes.
The first option can become financially painful.
The second option can become operationally painful.
Beep is my attempt to reduce that tradeoff.
I want the economics of VPS infrastructure with more of the experience of a modern cloud platform.
Not for toy projects.
Not for massive enterprise infrastructure.
For small teams building real products that need to be reliable without spending too much or hiring a full infrastructure team too early.
What I want Beep to become
I want Beep to be the layer between your product and your servers.
You bring your app. Beep helps you deploy it, run it, observe it, scale it, and understand it.
The important part is understand.
I do not want Beep to become another black box where developers click a button and have no idea what is happening underneath. That is useful until something breaks.
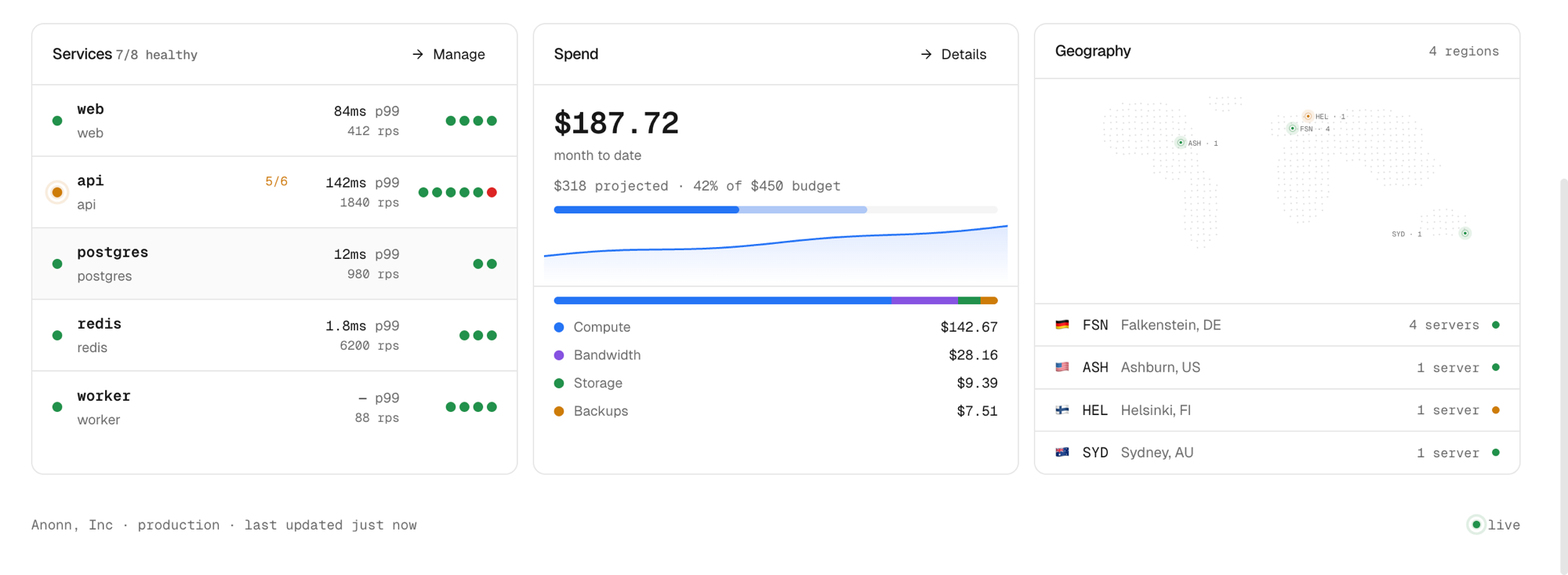
I want Beep to make the important parts visible:
- which server is this service running on?
- how much memory is it using?
- why did this deployment fail?
- what changed between the last deploy and this one?
- is this service healthy?
- are workers falling behind?
- is the database under pressure?
- what happens if this server dies?
- who changed this environment variable?
- what should the team look at before customers are affected?
- can this pull request be tested in a full-stack preview environment?
- did this AI-generated change actually work when deployed?
That is the kind of platform I want when running production systems.
Simple enough to move fast.
Explicit enough to debug.
Cheap enough for small teams.
Reliable enough for serious products.
Why I care
A lot of infrastructure work is invisible when things are going well.
Nobody notices the database migration that did not break anything. Nobody notices the background job that recovered properly. Nobody notices the server that was replaced before it caused downtime. Nobody notices the alert that fired early enough for someone to fix the issue before customers saw it.
But that invisible work is what keeps products alive.
Working on infrastructure at Chatarmin has made this obvious to me. The more important the product becomes, the more reliability matters. The more customers depend on it, the less acceptable it becomes for the system to rely on luck, memory, or someone being awake at the right time.
This is also why I care about preview environments.
As teams start relying more on AI agents and faster engineering workflows, the cost of reviewing changes manually will keep increasing. It will not be enough to ask whether the code looks right. Teams will need better ways to test whether the system still behaves correctly.
That means safer environments.
Real environments.
Disposable environments.
Full-stack environments.
Environments that let teams move quickly without turning production into the testing ground.
Beep is me trying to turn those lessons into a product.
A deployment platform for teams that want the cost and control of VPS infrastructure, with the operational guardrails of a modern cloud platform: reliable deployments, observability, autoscaling, access control, and full-stack preview environments.
That is why I’m building Beep.